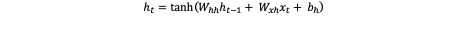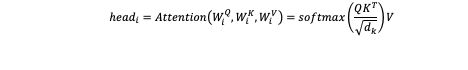Large Language Models (LLMs) are Artificial Intelligence algorithms that use massive data sets to summarize, generate and reason about new content. LLMs are built on a set of neural networks based on the transformer architecture. Each transformer consists of encoders and decoders that can understand text sequence and the relationship between words and phrases in it.
The generative AI technologies that have been enabled by LLMs have transformed how organizations serve their customers, how workers perform their jobs and how users perform daily tasks when searching for information and leveraging intelligent systems. To build an LLM we need to define the objective of the model and whether it will be chatbot, code generator or a summarizer.
Building an LLM
Building an LLM requires the curation of vast datasets that enable the model to gain a deep understanding of the language, vocabulary and context around the model’s objective. These datasets can span terabytes of data and can be grown even further depending on the model’s objectives [1].
Data collection and processing
Once the model objectives are defined, data can be gathered from sources on the internet, books and academic literature, social media and public and private databases. The data is then curated to remove any low-quality, duplicate or irrelevant content. It is also important to ensure that all ethics, copyright and bias issues are addressed since those areas can become of major concern as the model develops and begins to produce the results and predictions it is designed to do.
Selecting the model architecture
Model selection involves selecting the neural network design that is best suited for the LLM goals and objectives. The type of architecture to select depends on the tasks the LLM must support, whether it is generation, translation or summarization.
Perceptrons and feed-forward networks: Perceptrons are the most basic neural networks consisting of only input and output layers, with no hidden layers. Perceptrons are most suitable for solving linear problems with binary output. Feed-forward networks may include one or more layers hidden between the input and output. They introduce non-linearity, allowing for more complex relationships in data [2].
Recurrent Neural Networks (RNNs): RNNs are neural networks that process information sequentially by maintaining a hidden state that is updated as each element in the sequence is processed. RNNs are limited in capturing dependencies between elements within long sequences due to the vanishing gradient problem, where the influence of distant input makes it difficult to train the model as their signal becomes weaker.
Transformers: Transformers apply global self-attention that allows each token to refer to any other token, regardless of distance. Additionally, by taking advantage of parallelization, transformers introduce features such as scalability, language understanding, deep reasoning and fluent text generation to LLMs that were never possible with RNNs. It is recommended to start with a robust architecture such as transformers as this will maximize performance and training efficiency.
Figure 1. Example of an LLM architecture [3].
Implementing the model
Implementing the model requires using a deep learning framework such as TensorFlow or PyTorch to design and assemble the model’s core architecture [4]. The key steps in implementing the model are:
Defining the model architecture such as transformers and specifying the key parameters including the number of heads and layers.
Implementing the model by building the encoder and decoder layers, the attention mechanisms, feed-forward networks and normalizing the layers.
Designing input/output mechanisms that enable tokenized text input and output layers for predicted tokens.
Using modular design and optimizing resource allocation to scale training for large datasets.
Training the model
Model training is a multi-phase process requiring extensive data and computational resources. These phases include:
Self-supervised learning where the model is fed massive amounts of data, so that it can be trained in language understanding and predicting missing words in a sequence.
Supervised learning where the model is trained to understand prompts and instructions allowing it to generalize, interact and follow detailed requests.
Reinforcement learning with Human Feedback (RLHF) involves learning with human input to ensure that output matches human expectations and desired behaviour. This also ensures that the model avoids bias and harmful responses and that the output is helpful and accurate.
Fine tuning and customization
Customization techniques include full model fine-tuning where all weights in the model are adjusted to focus on task-specific data. It is also possible to fine-tune parameters and engineer prompts to focus on smaller modules, saving resources and enabling easier deployment.
Training a pre-trained model based on domain-specific datasets allows the model to specialize on target tasks. This is easier and less resource-intensive than training a model from scratch since it leverages the base knowledge already learned by the model.
Model deployment
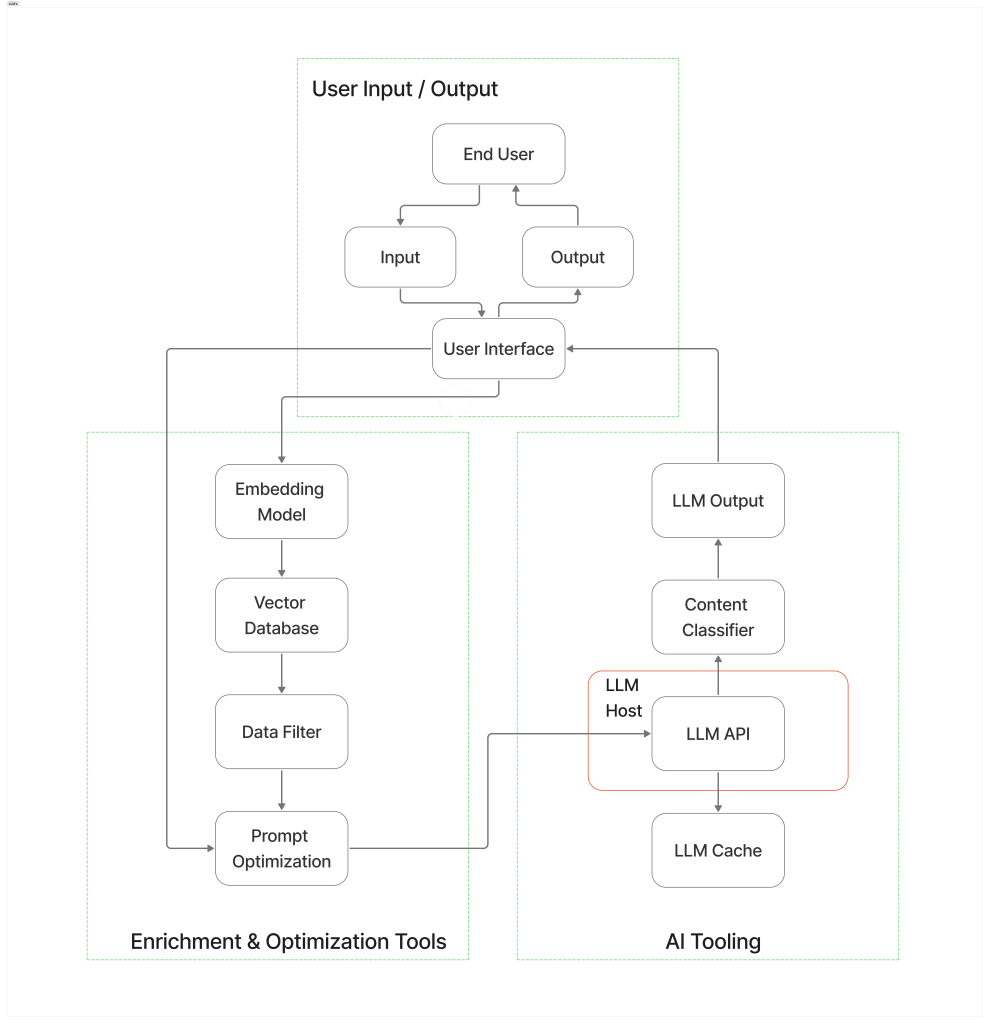
Deploying the LLM makes it available for real-world use, enabling users to interact with it. The model is deployed on local servers or cloud platforms using APIs to allow other applications or systems to interface with it. The model is scaled across multiple GPUs to handle the growing usage and improve performance [5]. The model is continually monitored, updated and maintained to ensure it remains current and accurate.
Ethical and legal considerations
The ethical and legal considerations are important in the development and deployment of LLMs. It is important that the LLM is unbiased and that it avoids propagating unfair and discriminatory outputs. This extends to discriminatory and harmful content which can be mitigated through reinforcement learning with human feedback (RLHF).
Training data may contain sensitive and private information, and the larger the datasets used to train the model the greater the privacy risks they involve. It is essential that privacy laws are adhered to and followed to ensure the models can continue to evolve and develop while preventing unintended memorization or leakage of private information.
Copyright and intellectual property must also be protected by ensuring that the proper licenses are obtained. Regular risk and compliance assessments and proper governance and oversight over the model life cycle can help mitigate ethical and legal issues.
Conclusion
Developing and deploying an LLM in 2025 requires a combination technical, analytical and soft skills. Strong programming skills in Python, R and Java are critical to AI development. A deep understanding of machine learning and LLM architectures including an understanding of the foundational mathematical concepts underlying them, are also critical. It is also important to have a good understanding of hardware architectures including CPUs, GPUs, TPUs and NPUs to ensure that the tasks performed by the LLM are deployed on the most suitable hardware to ensure efficiency, scalability and cost-effectiveness.
Other skills related to data management, problem-solving, critical thinking, communication and collaboration, and ethics and responsible AI are also essential in ensuring the models remain useful and sustainable.
While LLMs and their revolutionary transformer technology continue to impress us with new milestones, their foundations are deeply rooted in decades of research conducted in neural networks at countless institutions, and through the work of countless researchers.
Introduction
Large Language Models (LLMs) have gained momentum over the past five years as their use proliferated in a variety of applications, from chat-based language processing to code generation. Thanks to the transformer architecture, these LLMs possess superior abilities to capture the relationships within a sequence of text input, regardless of where in the input those relationships exist.
Transformers were first introduced in a 2017 landmark paper titled “Attention is all you need” [1]. The paper introduced a new approach to language processing that applied the concept of self-attention to process entire input sequences in parallel. Prior to transformers, neural architectures handled data sequentially, maintaining awareness of the input through hidden states that were recurrently updated with each step passing its output as input into the next.
LLMs are only an evolution of decades old artificial intelligence technology that can be traced back to the mid 20th century. While the breakthroughs of the past five years in LLMs have been propelled by the introduction of transformers, their foundations were established and developed over decades of research in Artificial Intelligence.
The History of LLMs
The foundations of Large Language Models (LLMs) can be traced back to experiments with neural networks conducted in the 1950s and 1960s. In the 1950s, researchers at IBM and Georgetown University investigated ways to enable computers to perform natural language processing (NLP). The goal of this experiment was to create a system that allowed translation from Russian to English. The first example of a chatbot was conceived in the 1960s with “Eliza”, designed by MIT’s Joseph Weizenbaum, and it established the foundations for research into natural language processing.
NLPs relied on simple models like the Perceptron, which were simple feed-forward networks without any recurrence features. Perceptrons were first introduced by Frank Rosenblatt in 1958. They were a single-layer neural network, based on an algorithm that classified input into two possible categories, and tweaked its predictions over millions of iterations to improve accuracy [3]. In the 1980s, the introduction of Recurrent Neural Networks (RNNs) improved on perceptrons by handling data sequentially while maintaining feedback loops in each step, further improving learning capabilities. RNNs were better able to understand and generate sequences through memory and recurrence, something perceptrons could not do [4]. Modern LLMs improved further on RNNs by enabling parallel rather than sequential computing.
In 1997, Long Short-Term Memory (LSTM) networks introduced deeper and more complex neural networks that could handle greater amounts of data. Fast forward to 2019, a team of researchers at Google introduced the Bidirectional Encoder Representations from Transformers (BERT) model. BERT’s innovation was its bidirectionality which allowed the output and input to take each other’s context into account. This allowed the pre-trained BERT to be fine-tuned with just one additional output layer to create state-of-the-art models for a range of tasks [5].
From 2019 onwards, the size and capabilities of LLMs grew exponentially. By the time OpenAI released ChatGPT in November 2022, the size of its GPT models was growing in staggering amounts, until it reached an estimated 1.8 trillion parameters in GPT-4. These parameters include learned model weights that control how input tokens are transformed layer by layer, as discussed later in this article. ChatGPT allows non-technical users to prompt the LLM and receive a response quickly. The more the user interacts with the model, the better the context it can build, thus allowing it to maintain a conversational type of interaction with the user.
The LLM race was on. All the key industry players began releasing their own versions of LLMs to compete with OpenAI. To respond to ChatGPT, Google released Bard, while Meta introduced LLaMA (Large Language Model Meta AI). Microsoft had partnered with OpenAI in 2019 and built a version of its Bing search engine powered by ChatGPT. DataBricks also released its own open-source LLM, named “Dolly”
Understanding Recurrent Neural Networks (RNNs)
The inherent characteristic of Recurrent Neural Networks (RNNs) is their memory or hidden state. RNNs process input sequentially, token by token, with each step considering the current input token and the current hidden state to calculate a new hidden state. The hidden state acts as a running summary of the information seen so far in the sequence. RNNs understand a sequence by processing them word by word, while keeping a running summary of the words seen so far [6].
The recurrent structure of RNNs means that they perform the same computation at each step, with their internal state changing based on the input sequence. Therefore, if we have an input sequence x = (x1, x2, …, xt), the RNN updates its hidden state ht at time step t using the current input xt and the previous hidden state ht-1. This can be formulated as:
Where:
ht is the new hidden state at time step t
ht-1 is the hidden state from the previous time step
xt is the input vector at time step t
Whh and Wxh are the shared weight matrices across all time steps for hidden-to-hidden and input-to-hidden connections, respectively.
bh is a bias vector
tanh is a common activation function (hyperbolic tangent), introducing non-linearity.
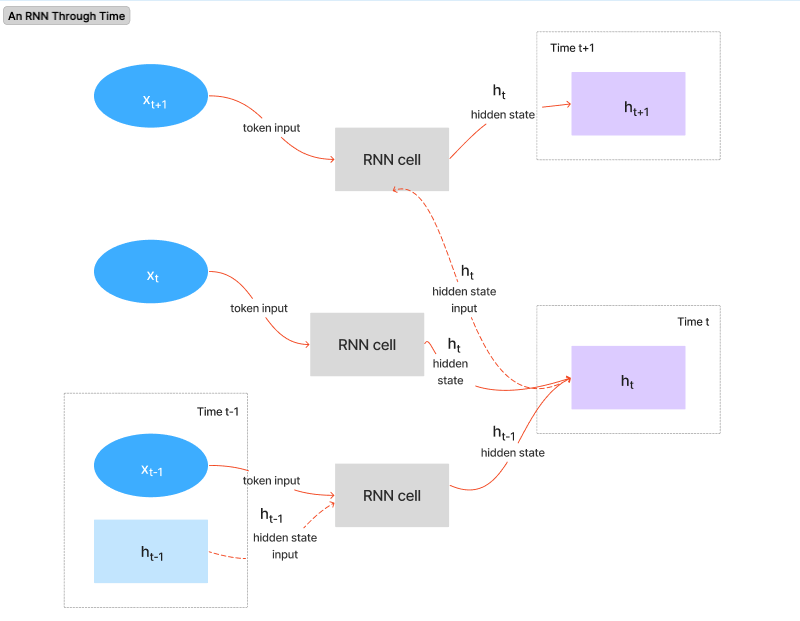
This process can be visualized by breaking out the RNN timeline to show a snapshot of the system at each step in time, and how the hidden state is updated and passed from one step to the next.
Figure 1. An RNN through time. The RNN cell processes input and the hidden state from time t-1 to produce the hidden state that is used as input together with token input from time t.
Limitations of RNNs
The sequential nature of RNNs limits their ability to process tasks that contain long sequences. This may be one of the main limitations that gave rise to the development of the transformer architecture and the need to process sequences much faster and in parallel. The following are some of the main limitations of RNNs.
Limitations in modeling long-range dependencies: RNNs are limited in capturing dependencies between elements within long sequences. This limitation is due primarily to the vanishing gradient problem. As gradients (error signals) occur during later steps in time, it becomes increasingly more difficult for the signal to flow backwards to earlier time steps and adjust the weights. This is because the longer the sequence the fainter the signal becomes. As the signal becomes weaker, by the time it reaches the relevant steps it becomes increasingly more difficult for the network to learn and trace back the relationship between those earlier inputs and the later outputs.
Sequential processing: RNNs process sequences token by token, in order. Hidden states must also be processed sequentially such that to obtain the hidden state at time t, the RNN must use the hidden state from t-1 as input. Modern hardware like GPUs and TPUs are well equipped to work with parallel computation. RNNs are unable to make use of this hardware due to their sequential processing, which leads to longer training times compared to parallel architectures.
Fixed size of hidden states: In the sequence-to-sequence model, the encoder must process and compress the entire input sequence into a single fixed size vector. This vector is then passed to the RNN decoder which is used to generate the output for the next hidden state. The compression of potentially long and complex input sequences into fixed-size vectors can be challenging. It also makes it difficult to retrain the network on all the input details that may have been compressed, and thus potentially causing some important information required for training to be missed.
How Transformers Replaced Recurrence
The limitations of RNNs in optimizing learning over large sequences and their sequential processing gave rise to the transformer architecture. Instead of sequential processing, transformers introduced self-attention, enabling the network to learn from any point in the sequence, regardless of distance.
Self-attention in transformers is analogous to the way humans process long sequences of text. When we attempt to translate text or process complex sequences, we do not read the entire text and then attempt to translate or understand it. Instead, we tend to go back and review parts of the text that we determine are most relevant to our understanding of it, so that we can generate the output we are trying to produce. In other words, we pay attention to the most relevant parts of the input that will help us generate the output. Transformers apply global self-attention that allows each token to refer to any other token, regardless of distance. Additionally, by taking advantage of parallelization, transformers introduce features such as scalability, language understanding, deep reasoning and fluent text generation to LLMs that were never possible with RNNs.
How Transformers Pay Attention
Self-attention enables the model to refer to any token in the input sequence and capture any complex relationships and dependencies within the data [7]. Self-attention is computed through the following steps.
1. Query, Key, Value (Q,K,V) matrices
Query (Q): Represents what current information is required or must be focused on. This can be described by asking the question “What information is the most relevant right now?”
Key (K): Keys act as identifiers for each input element. They are compared against the input sequence to determine relevance. This is analogous to asking the question “does this input token match the information I am looking for?”
Value (V): Values are also associated with each input token and represent the content or the meaning of that token. Values are weighted and summed to produce the context vector, which can be described as “this is the information I have”.
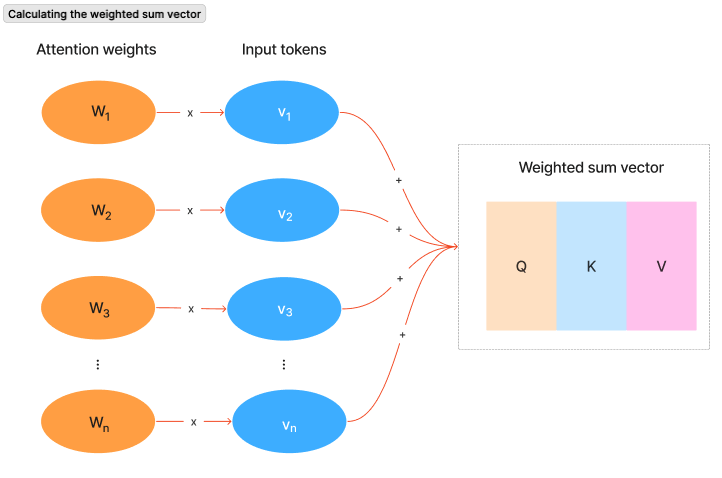
The model performs a lookup for each Query across all Keys. The degree to which a Query matches a Key determines the weight assigned to the corresponding Value. The model then calculates a weight or an attention score that determines how much attention a token should receive when generating predictions. The attention scores are used to calculate a weighted sum of all the Value vectors from the input sequence. The result is a vector containing the weighted sum of all the weighted value vectors.
Figure 2. Calculating the weighted sum vector. Attention scores are multiplied by the Value (input) vectors which are then summed to produce the weighted sum vector.
We have already discussed how traditional RNNs struggle to retain information for distant input due to the sequential nature of their hidden state. Attention, on the other hand, allows the model to consider the weights of all inputs and by summing them up. The resulting vector incorporates information from all inputs with the proper weights assigned to them. This allows the model to have a context of all input, while focusing on the most relevant information in the sequence, regardless of their distance.
2. Multi-head attention
When we consider a sentence, we do not consider it one word at a time. Instead, we look at each specific word in the sentence and consider whether it is the subject or the object. We also consider the overall grammar to make sense of the sentence and what it is trying to convey.
The same analogy applies when calculating attention. Instead of performing a single attention calculation for the Q, K, V vectors, multiple calculations are performed each on a single attentionhead, such that each head looks at a different pattern or relationship in the sequence. This is the concept of multi-head attention which allows the parallel processing of the Q, K, V vectors. It allows the model to look at different patterns or relationships within the sequence.
3. Masked multi-head self-attention
Masking ensures that the head focuses only on the tokens received so far when generating output, without looking ahead into the input sequence to generate the next token.
Attention score: The dot product of the Q and K matrices is used to determine the alignment of each Query with each Key, producing a square matrix reflecting the relationship between all input tokens.
Masking: A mask is applied to the resulting attention matrix to positions the model is not allowed to access, thus preventing it from ‘peeking’ when predicting the next token.
Softmax: After masking, the attention score is converted into probability using the Softmax function. The Softmax function applies a probability distribution to a vector whose size matches the vocabulary of the model, called logits. For example, if the model has a vocabulary of 50,000 words, the output logits vector will have a dimension of 50,000. Each element in the logits vector corresponds to a score for one specific token in the vocabulary. The Softmax function takes the logits vector as input, and outputs a probability vector that represents the model’s predicted probability distribution over the entire vocabulary of the model for the current position in the output sequence.
When it calculates attention for the Q, K, V vectors, the model does not recalculate attention for the same original Q, K, V vectors. Rather, it learns separate linear projections for each head. If we have h attention heads, then each head i learns the projection matrices
Each head performs the scaled Dot-Product Attention calculation using its projected Qi, Ki, Vi:
Where dk is the dimension of the Ki vectors within each head. Each projection of Qi, Ki, Vi allows a head to focus on and learn from a different representation of the original input. By running these calculations in parallel the model can learn about different types of relationships within the sequence.
4. Output and concatenation
The final step is to concatenate the output from all attention heads and apply a linear projection, using a learned weight matrix, to the concatenated output. The concatenated output is fed into another linear feedforward layer, where it is normalized back to a constant size to preserve the original meaning of the input before it is passed deeper into additional layers in the network [8].
Conclusion
There is no doubt that transformers have revolutionized the way LLMs have been deployed and applied in a variety of applications, including chatbots, content creation, agents and code completion. By relying on large and ever-growing volume of parameters, and an architecture that is designed for scalability and parallel computing, we are only beginning to discover the breadth of applications transformers can have.
As the challenges facing LLMs continue to be overcome, such as the ethical and environmental concerns, we can expect them to continue to become more efficient, more powerful and ultimately more intelligent. While LLMs and their revolutionary transformer technology continue to impress us with new milestones, their foundations are deeply rooted in decades of research conducted in neural networks at countless institutions, and through the work of countless researchers.
References
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin. “Attention Is All You Need.” In Proceedings of the 31st Conference on Neural Information Processing Systems (NeurIPS 2017). arXiv:1706.03762 cs.CL, 2017
Large Language Models (LLMs) are Artificial Intelligence algorithms that use massive data sets to summarize, generate and reason about new content. LLMs use deep learning techniques capable of broad range Natural Language Processing (NLP) tasks. NLP tasks are those involving analysis, answering questions through text translation, classification, and generation [1][2].
Put simply, LLMs are computer programs that can interpret human input and complex data extremely well given large enough datasets to train and learn from. The generative AI technologies that have been enabled by LLMs have transformed how organizations serve their customers, how workers perform their jobs and how users perform daily tasks when searching for information and leveraging intelligent systems.
The core principles of LLMs
LLMs are built on a set of neural networks based on the transformer architecture. Each transformer consists of encoders and decoders that can understand text and the relationship between words and phrases in it. The transformer architecture relies on the next-word prediction principle which allows predicting the most probable next work based on a text prompt from the user. Transformers can process sequences in parallel which enables them to learn and train much faster [2][3][4]. This is due to their self-attention mechanism which enables transformers to process sequences and capture distant dependencies much more effectively than previous architectures.
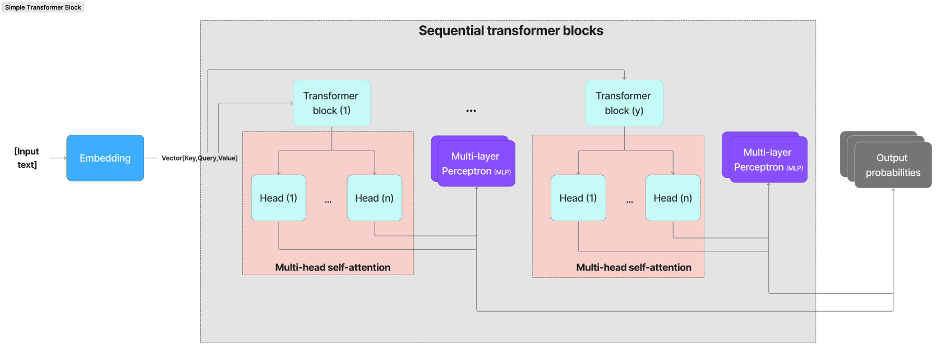
The transformer architecture consists of three key components:
Embedding: To generate text using the transformer model, the input must be converted into a numerical format that can be understood by the model. This process involves three steps that involve 1) tokenizing the input and breaking it down into smaller, more manageable pieces 2) embedding the tokens in a matrix that allows the model to assign semantic meaning to each token 3) encoding the position of each token in the input prompt 4) final embedding by taking the sum of the tokens and positional encodings, and capturing the position of the tokens in the input sequence.
Transformer block: comprises of multi-head self-attention and a multi-layer Perceptron layer. Most models stack these blocks sequentially, allowing the token representations to evolve though layers of blocks which in turn allows the model to build an intricate understanding of each token.
Output probabilities: Once the input has been processed through the transformer blocks, it passes through the final layer that prepares it for token prediction. This step projects a final representation into a dimensional space where each token is assigned a likelihood of being the next word. A probability distribution is applied to determine the next token based on its likelihood, which in turn enables text generation.
LLM applications
The transformer architecture allows LLMs to achieve a massive scale of billions of parameters. LLMs begin with pre-training on large datasets of text, grammar, facts and context. Once pre-trained, the models undergo fine-tuning where labeled datasets are used to adapt the models to specific tasks. The ability of LLMs to use billions of parameters, combined with their efficient attention mechanisms and their training capabilities, allows LLMs to power modern AI applications such as chatbots, content creation, code completion and translation.
Text generation: Chatbots and content creation
Text generation is one of the most prominent applications of LLMs where coherent and context-relevant text is automatically produced. This application of LLMs powers chatbots, like ChatGPT, that interact with users by answering questions, providing recommendations, generating images and conducting research [5].
GPT 4.5 and 4o feature multimodal capabilities allowing them to handle text and images for versatile use in different applications, and they can both handle text processing capacity of 25,000 words, though the amount of computational resources varies between the two models.
By leveraging their vast datasets, LLMs are also used for content creation such as social media posts, product descriptions and marketing. Tools like Copy.ai and Grammarly use LLMs to generate marketing copy, and assist with grammar and text editing. DeepL Translator uses LLMs trained on linguistic data for language translation.
Agents
Agentic LLMs refer to conversational programs such as chatbots and intelligent assistants that use transformer-based architectures and Recurrent Neural Networks (RNNs) to interpret user input, process sequential data such as text, and generate coherent, personalized responses [6]. Personalized responses to input text are achieved through context-awareness and analyzing conversations.
Agentic LLMs are also capable of managing complex workflows and can collaborate with other AI agents for better analysis. Vast datasets can be leveraged to support a variety of domains such as healthcare, finance and customer support.
Code completion
Code completion is a leading application of LLMs that uses the transformer-based architecture to generate and suggest code by predicting next tokens, statements or entire code blocks. In this context, transformer models are trained using self-attention mechanisms to enable code understanding and completion predictions [7]. The encoder-decoder transformer model is used such that the input is code surrounding the cursor (converted into tokens), and the output is a set of suggestions to complete the current or multiple lines.
Challenges and future directions
Large Language Models are still facing challenges related to ethical and privacy concerns, maintaining accuracy, avoiding bias, and managing high resource consumption [8].
Ethical concerns: LLMs are trained on massive datasets. There are still open questions as to who can use these datasets, and how and when they can be used. These datasets can also be biased and lead to biased output from LLMs, which can lead to misinformation and hate speech.
Data privacy: The use of massive datasets containing large amounts of user data poses significant privacy concerns. Safeguards in the use of data are required to train a model without compromising user privacy. As the use of LLMs becomes more mainstream, and as the size of datasets used to train them increases, so do the privacy concerns around their use.
Output bias: Existing biases in the available training data can cause LLMs to amplify those biases, leading to inaccurate and misleading results. This is particularly important for areas that require objective data analysis and output, such as law, healthcare and economics.
Hallucinations: LLMs are prone to “hallucinations” where the model output may seem reasonable, yet the information provided is incorrect. Hallucinations can be addressed through better training and validation methodologies to enhance the reliability of generated content.
Environmental impact: Training and deploying LLMs requires an extensive amount of energy resources, leading to increased carbon emissions. There is a need to develop more efficient algorithms while also investing in renewable and efficient energy generation that will lower the carbon footprint of LLMs, especially as their use and application accelerate.
Addressing these and other challenges such as regulatory compliance, security and cyber attacks will ensure that LLMs continue to use the correct input datasets while producing the correct output in an ethical, fair and unbiased manner. The integration of domain-specific knowledge through specialized fine tuning will also enable LLMs to produce more accurate and context-aware information that will maximize their benefits.
Conclusion
LLMs power a variety of applications, including chatbots to content creation, code completion and domain-specific automation. Using the transformer architecture and vast datasets to train and learn, they have emerged as a transformative discipline of artificial intelligence. LLMs have proved their outstanding capabilities in understanding, generating, and reasoning with natural language. While there are challenges to overcome for LLMs such as bias, accuracy, environmental impact, and domain specialization, it is expected that LLMs will become more efficient and trustworthy as algorithms improve and innovations are achieved through better fact-checking and human oversight.